Installation
The system is contained in a dynamic link library DLL, included in a NuGet package, which can be incorporated into any type of platform or software project in the .NET universe.
Direct integration into a .NET project can be done including the NuGet in the project itself and using the well-defined standard calls in the documentation or in Visual Studio's own intelligence system.
Open NuGet Package Manager in Visual Studio and search for 'Angelves' for access to our packages.
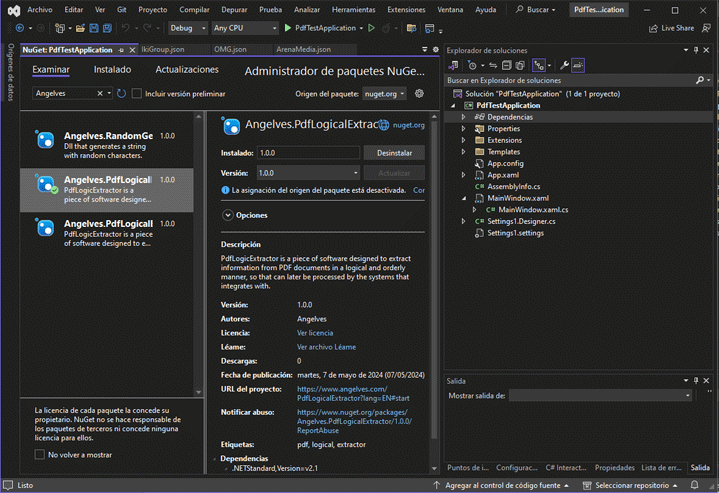
Manual installation by console:
PM> NuGet\Install-Package Angelves.PdfAndExcelLogicalExtractor -Version 1.1.0